The blog discuss about the technical approach on distributing domain files among distributed WebLogic domain infrastructure , means where multiple machines are installed with same WebLogic version installation but have to share the same domain to be used in distributed infrastructure.
Lets consider we have 2 machine mach1 and mach2 installed with WebLogic Server.
Machine1 (mach01) :
- Weblogic Server Installed
- Managed Servers (mach_ms1, mach_ms2)
- Domain: dev_soadomain
Machine2 (mach02) :
- Weblogic Server Installed
- Managed Servers (mach_ms3, mach_ms4)
Now , our requirement is to have machine2 to be part of the same domain dev_soadomain created in machine1 to be part of the clustered WebLogic domain
Distribute domain files to another WebLogic Server using pack and unpack
- Log into Machine1 Weblogic Server Admin User
- Navigate to WebLogic domain folder
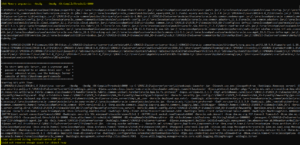
[wls@mach01]$ cd $WL_HOME/common/bin
- Run the below given command to pack the WebLogic domain file from machine1 (mach01)
[wls@mach01]$ ./pack.sh -domain=$DOMAIN_HOME-template=$WL_HOME/ common/templates/domains/DEV_SOADOMAIN_template.jar -template_ name=DEV_SOADOMAIN –managed=true
- A file is created at $WL_HOME/common/templates/domains/DEV_SOADOMAIN_template.jar
- Log into Machine2 Weblogic Server Admin User
- Naviage to weblogic domain folder
- Copy the DEV_SOADOMAIN_template.jar from machine1(mach01) to machine2(mach02)
[wls@mach02]$ scp wls@mach01:$WL_HOME/common/templates/domains/ DEV_SOADOMAIN_template.jar $WL_HOME/common/templates/domains/
- Unpack the DEV_SOADOMAIN_template.jar in machine2(mach02) domain folder
[wls@mach02]$ cd $WL_HOME/common/bin [wls@mach02]$ ./unpack.sh -template=$WL_HOME/common/templates/ domains/DEV_SOADOMAIN_template.jar –domain=$DOMAIN_HOME
- An entry to the DEV_SOADOMAIN domain will automatically be added to the nodemanager.properties file
Distribute domain files to another WebLogic Server manually
- Domain Directory in machine1
DOMAIN_HOME = oracle/Middleware/user_projects/domains/DEV_SOADOMAIN
- Log into Machine2 Weblogic Server Admin User
- Create the Domain Directory with the same name as in machine1
[wls@mach02]$ mkdir –p $DOMAIN_HOME
Copy the Domain files from machine1 to machine2
[wls@mach02]$ scp –rp wls@mach01:$DOMAIN_HOME $DOMAIN_HOME/..
Edit the e nodemanager.domains in machine1 and make the entry
[wls@mach01]$ vi $WL_HOME/common/nodemanager/nodemanager.domains DEV_SOADOMAIN=/oracle/Middleware/user_projects/domains/DEV_SOADOMAIN/