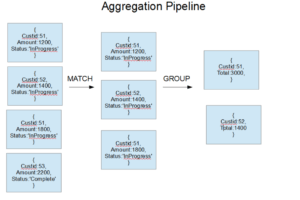
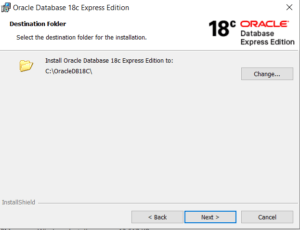
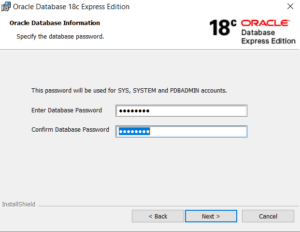
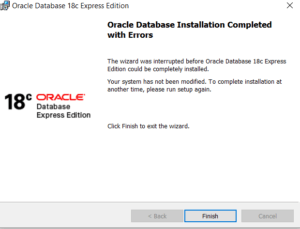
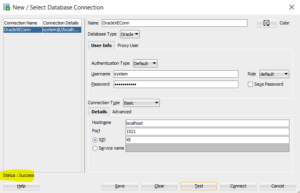
The The $bucket and $bucketAuto stage in the aggregate method in the MongoDB Aggregation Pipeline to allow the incoming document of a collection to be categorized into groups called buckets.
Point to Consider for $bucket Stage
- The incoming document of a collection to be categorized into buckets
- Each document in the bucket is applied with the groupby expression , specified by boundaries in the bucket
- A default value is specified when the documents in the bucket having groupBy values outside of the boundaries
- A default value is specified when the documents in the bucket having different BSON type than the values in boundaries
- The buckets arranges the input document using $sort if the groupBy expression resolves to an array or a document
- At least one document should be placed to form bucket.
$bucket Syntax
{
$bucket: {
groupBy: <expression>,
boundaries: [ <lowerbound1>, <lowerbound2>, ... ],
default: <literal>,
output: {
<output1>: { <$accumulator expression> },
...
<outputN>: { <$accumulator expression> }
}
}
}
$bucket document fields
The $bucket document contains the below given fields:
| Field | Type | Description |
| groupBy | expression | expressions are used to groupby the documents. Each input document either should be groupby using expression or document value should be specified with the boundaries range |
| Boundaries | Array |
indicates an array of values (values must be in ascending order and all of the same type) based on the groupBy expression that specify the boundaries for each bucket. The adjacent pair of values indicates lower boundary and upper boundary for the bucket. [4,8) with inclusive lower bound 4 and exclusive upper bound 8. |
| default | Literal |
indicates the _id of an additional bucket that contains all documents whose groupBy expression result does not fall into a bucket specified by boundaries. The default value can be of a different type than boundaries types and should be less than the lowest boundaries value, or greater than or equal to the highest boundaries value |
| output | Document |
indicates the fields to include in the output documents with _id field (in case of default value) using accumulator expressions <outputfield1>: { <accumulator>: <expression1> }, |
$bucketAuto Stage:
The $bucketAuto is similar to $bucket for grouping the incoming document but in the $bucketAuto it automatically determines the bucket boundaries to evenly distribute the documents into the specified number of buckets.
Point to Consider for $bucketAuto Stage
- Allows for grouping the incoming document
- Automatically determines the bucket boundaries to evenly distribute the documents into the specified number of buckets
- The _id.min field indicates the inclusive lower bound for the bucket
- The _id.max field indicates the exclusive upper bound for the bucket
- The final bucket in the series will have inclusive upper bound
- The count field that contains the number of documents in the bucket
$bucketAuto Syntax
{
$bucketAuto: {
groupBy: <expression>,
buckets: <number>,
output: {
<output1>: { <$accumulator expression> },
...
}
granularity: <string>
}
}
The $bucketAuto contains the below given fields:
| Field | Type | Description |
| groupBy | expression | used to groupBy the incoming documents |
| Buckets | integer | 32-bit integer that indicates the bucket count into which input documents are grouped |
| Output | document |
indicates the fields in the output documents with _id field by using accumulator expressions. The default count is to be added explicitly in the output document. output: { |
| Granularity | string |
indicates the preferred number series to calcualte the boundary edges end on preferred round numbers or their powers of 10. It can be applicable if the all groupBy values are numeric and none of them are NaN. Supported value for granularity are: “R5” |
The documents are ordered using $sort before determining the bucket boundaries if the groupBy expression refers to an array or document